Cloud computing changed how we build software. Elasticity, scalability, global reach. These benefits are real. Companies that moved to the cloud have seen faster deployments, reduced capital expenditure, and the ability to scale instantly.
But here's the uncomfortable truth: the cloud is also a house of cards. Most of us are standing on it without a safety net.
TL;DR
- Recent major outages at AWS, Azure, GitHub, and Cloudflare have exposed the risk of cloud concentration
- The "shadow stack" problem: Most SaaS tools run on the same underlying provider (usually AWS), creating hidden dependencies
- 80% of enterprises are now adopting hybrid cloud strategies to improve resilience and avoid vendor lock-in
- This article provides a practical 8-step playbook for implementing hybrid cloud architecture that withstands the next major outage
- The investment pays for itself: One prevented outage typically covers years of hybrid infrastructure costs
Part 1: The Cloud is Great, But You're Playing with Fire
The Concentration Problem is Real
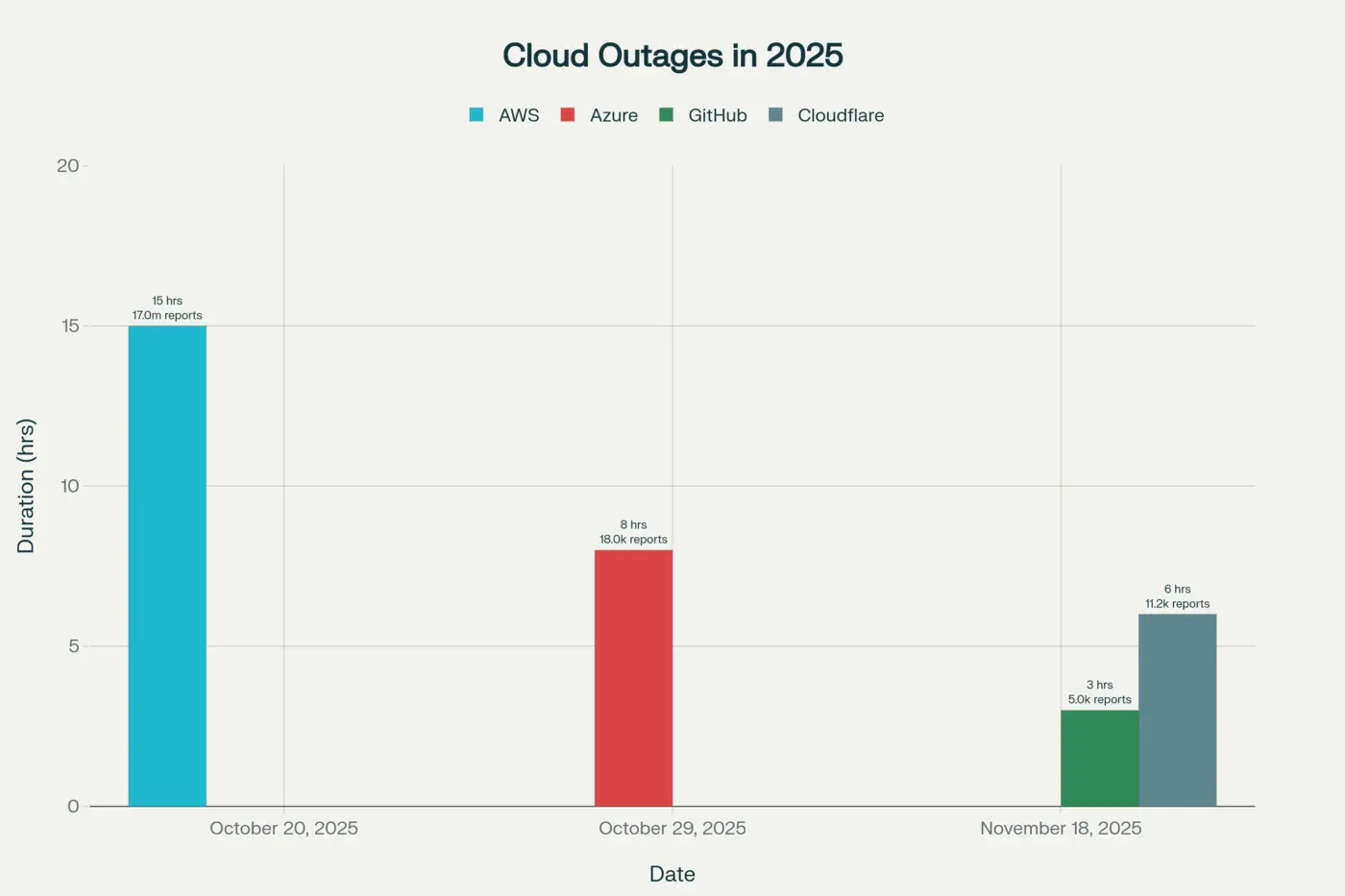
Last month (October 2025), we witnessed two cloud outages that took down significant portions of the internet. On October 20th, AWS's US-EAST-1 region failed for approximately 15 hours, bringing down Slack, Atlassian, and major UK banks like Barclays and Lloyds. Days later, Microsoft Azure experienced a similar ~8-hour global outage affecting Microsoft 365 and Xbox services, with over 18,000 users reporting issues with Azure alone.
Then came November 18th, 2025. A day that saw two major infrastructure outages simultaneously.
First, GitHub went down for approximately 3 hours. GitHub Actions failed. CI/CD pipelines stopped. Copilot went dark. Developers couldn't deploy. They couldn't merge. They couldn't fix issues.
Then Cloudflare (the infrastructure company sitting at the front door of the internet) went down, taking X (Twitter), ChatGPT, Spotify, and thousands of other websites with it. According to Cloudflare's official post-mortem, a database permissions change caused a Bot Management configuration file to double in size. This triggered an unhandled code panic that cascaded across their network. The Cloudflare outage lasted approximately 6 hours, from 11:20 UTC to 17:06 UTC.
Two critical infrastructure providers failing on the same day highlighted something everyone was quietly pretending wasn't a problem: we've consolidated the internet into a handful of companies' hands.
AWS holds 30% of the cloud market. Microsoft Azure holds 20%. Google Cloud Platform holds 13%. If you're using any of these (and statistically, you are), you're betting your business on their reliability.
The SaaS Stack Problem: Turtles All the Way Down
But it gets worse. It's not about using one cloud provider. Most companies are stacking SaaS on top of SaaS on top of cloud infrastructure.
Here's what a typical tech company's stack looks like in 2025:
- Your application runs on AWS (or Azure/GCP)
- Authentication happens via Okta or Auth0 (which runs on... AWS)
- Payments process through Stripe (runs on AWS)
- Monitoring happens via Datadog (you guessed it, AWS)
- Your team uses Slack (AWS)
- Project management via Atlassian (Jira, Confluence, Bitbucket, all on AWS)
- CDN and DDoS protection comes from Cloudflare
When one of these fails, the damage spreads beyond that service. It's a cascade. The November Cloudflare outage didn't affect Cloudflare customers directly. It affected OpenAI, which meant ChatGPT went down, which meant countless applications integrating ChatGPT went down. One company's failure became everyone's problem.
Vendor Lock-In: The Other Silent Killer
Moving between cloud providers is expensive and difficult. AWS charges steep "data egress" fees to move data out. Switching from Azure to another provider means rewriting integrations, retesting applications, and managing complex migrations. This lock-in means that if you want to leave a provider after an outage, you often cannot afford to.
Studies show that this vendor lock-in costs organizations millions. In 2024, the UK Cabinet Office warned that overreliance on AWS could cost public bodies £894 million. Microsoft faced antitrust penalties linked to licensing practices that discouraged customers from leaving Azure.
The Real Cost of Downtime
During the October AWS outage, Downdetector recorded over 17 million user reports from more than 60 countries, a 970% spike from normal traffic. This wasn't a minor blip. This was a global infrastructure failure.
Every minute of downtime costs businesses money, sometimes thousands per minute. Yet we continue to design systems that have a single point of failure.
Part 2: Stop Stacking SaaS. Your Tools Are Making You Vulnerable
The "Shadow Stack" Problem
It's 2025, and engineers solve problems by adding tools. Need authentication? Add Okta. Need monitoring? Add Datadog. Need payments? Add Stripe. Each tool solves a specific problem well, but together, they create a hidden dependency network:
Your App
├── Runs on AWS
│ └── Uses IAM, which uses AWS KMS for encryption
├── Logs to Datadog
│ └── Which runs on AWS
├── Authenticates via Okta
│ └── Which connects through Cloudflare
├── Processes payments via Stripe
│ └── Which relies on multiple cloud providers
├── Team communicates via Slack
│ └── Which runs on AWS
└── Projects managed via Atlassian (Jira, Confluence, Bitbucket)
└── Which runs on AWS
When Cloudflare went down on November 18th, 2025, it didn't affect companies using Cloudflare directly. It affected OpenAI, which affected every company using OpenAI's APIs. It affected ChatGPT integrations built into hundreds of applications.
One company's failure cascaded through the entire ecosystem because we've all standardized on the same underlying infrastructure.
The SaaS Vendor Concentration Risk
A study in 2025 found that 58% of organizations suffered a SaaS security incident in the past 18 months. Many of these were linked to tools adopted outside IT or compliance oversight, what's called the "shadow stack."
But the official tools are risky too. Consider these scenarios:
Scenario 1: The Okta Breach If Okta (which handles authentication for thousands of companies) is breached or goes down, companies lose login access. Not to their SaaS tools. Not to their cloud infrastructure. Not to anything.
Scenario 2: The Builder.ai Bankruptcy In 2025, Builder.ai went bankrupt and locked customers out of their source code and data. No warning. No migration plan. Years of development work became inaccessible.
Scenario 3: The Pricing Shock VMware customers saw price increases of up to 10x after a change in ownership. When you're locked into a tool, you have no negotiating power.
The Dependency Chain is Getting Longer, Not Shorter
Most B2B SaaS companies run on nearly identical infrastructure stacks. A Forrester study found that:
- 92% of enterprises have adopted multi-cloud strategies
- 87% of organizations have implemented multi-cloud approaches
- But 73% of companies still concentrate on public and private clouds without geographic diversification
This means that while companies are spreading across multiple clouds, they still depend on the same underlying services. They're betting on multiple versions of the same risk.
When a tool like Okta or Cloudflare goes down, it doesn't matter if you're on AWS or Azure. You're both down.
Part 3: Hybrid Cloud Isn't a Step Backward. It's a Step Forward
When people hear "hybrid cloud," they often think it's a compromise. A stepping stone to "real cloud." Something you do because you're stuck with legacy systems.
That's wrong.
Hybrid cloud in 2025 isn't about being stuck in the past. It's about being in control of your future.
What Hybrid Cloud Is
Hybrid cloud means combining on-premises or private cloud infrastructure (that you control), public cloud services (for elasticity and specialized capabilities), multiple cloud providers (to avoid lock-in), and centralized management (so you're not juggling different systems).
The key insight is this: you run workloads where they should run, not where vendors want them to run.
Sensitive or mission-critical data? On-premises, behind your firewall. Bursty, experimental workloads? Public cloud, scaled automatically. Heavy analytics training? Cloud GPU resources. Inference serving? On-premises for low latency.
This isn't a compromise. This is optimization.
The Business Case is Clear
Organizations that have adopted hybrid cloud are seeing improvements:
Resilience and Uptime
- Redundancy across two distinct environments means if a cloud region fails, on-premises systems keep serving users
- If your data center is affected by a physical disaster, cloud replicas take over
- Recovery time objectives (RTO) drop because you have multiple failover paths
- Studies show hybrid cloud adoption grew from 73% in 2023 to 80% in 2025, with 54% of enterprises using it for mission-critical workloads
Cost Management
- Predictable workloads run on on-premises infrastructure, avoiding cloud's variable costs
- Seasonal peaks burst into public cloud instead of requiring over-provisioning
- Companies eliminate the cost of maintaining underutilized on-premises hardware for "in case" scenarios
- A case study of a leading manufacturer saw 40% reduction in bandwidth costs by moving to a hybrid model with direct cloud connections
Data Sovereignty and Compliance
- GDPR requires data residency in EU regions. Hybrid cloud lets you keep it there
- HIPAA-regulated healthcare data stays on-premises, fully under your control
- Financial services data doesn't leave your jurisdiction
- You process locally, then send anonymized insights to the cloud for training
- This isn't possible with pure cloud: you'd violate compliance requirements
Vendor Negotiation Power
- When you're not entirely dependent on AWS, you negotiate better rates
- You shift workloads between providers based on pricing and performance
- You're not locked in, so vendors have to earn your business
Why This Works Better in a Multi-Outage World
The events of October and November 2025 proved one thing: centralized systems fail at scale.
When AWS US-EAST-1 failed, companies relying entirely on that region went down. When Cloudflare failed, companies that had put all their traffic through Cloudflare lost access to their services.
But companies with hybrid cloud? They had options.
If your main application runs on AWS but you have a fallback on-premises, you stay alive. If you have authentication on-premises backed by Okta, you stay alive when Okta has issues. If your database replicates across AWS and your private data center, one regional outage doesn't mean data loss.
This isn't theoretical. This is proven architecture.
"We Kept Running While Our Competitors Went Dark"
"During the October AWS outage, our primary services failed over to our on-premises infrastructure in under five minutes. Our core operations continued uninterrupted while competitors scrambled. It was the ultimate validation of our hybrid strategy. The investment paid for itself in a single afternoon."
— CIO, Mid-Market Logistics Company
Part 4: The Data Shows It. 80% of Enterprises Are Moving to Hybrid Cloud
In 2023, 73% of enterprises had adopted hybrid cloud. Today, in 2025, that number is 80%.
This isn't a coincidence. This isn't enterprises being stuck in the past. This is a deliberate, rapid shift toward architectural resilience.
Adoption Data
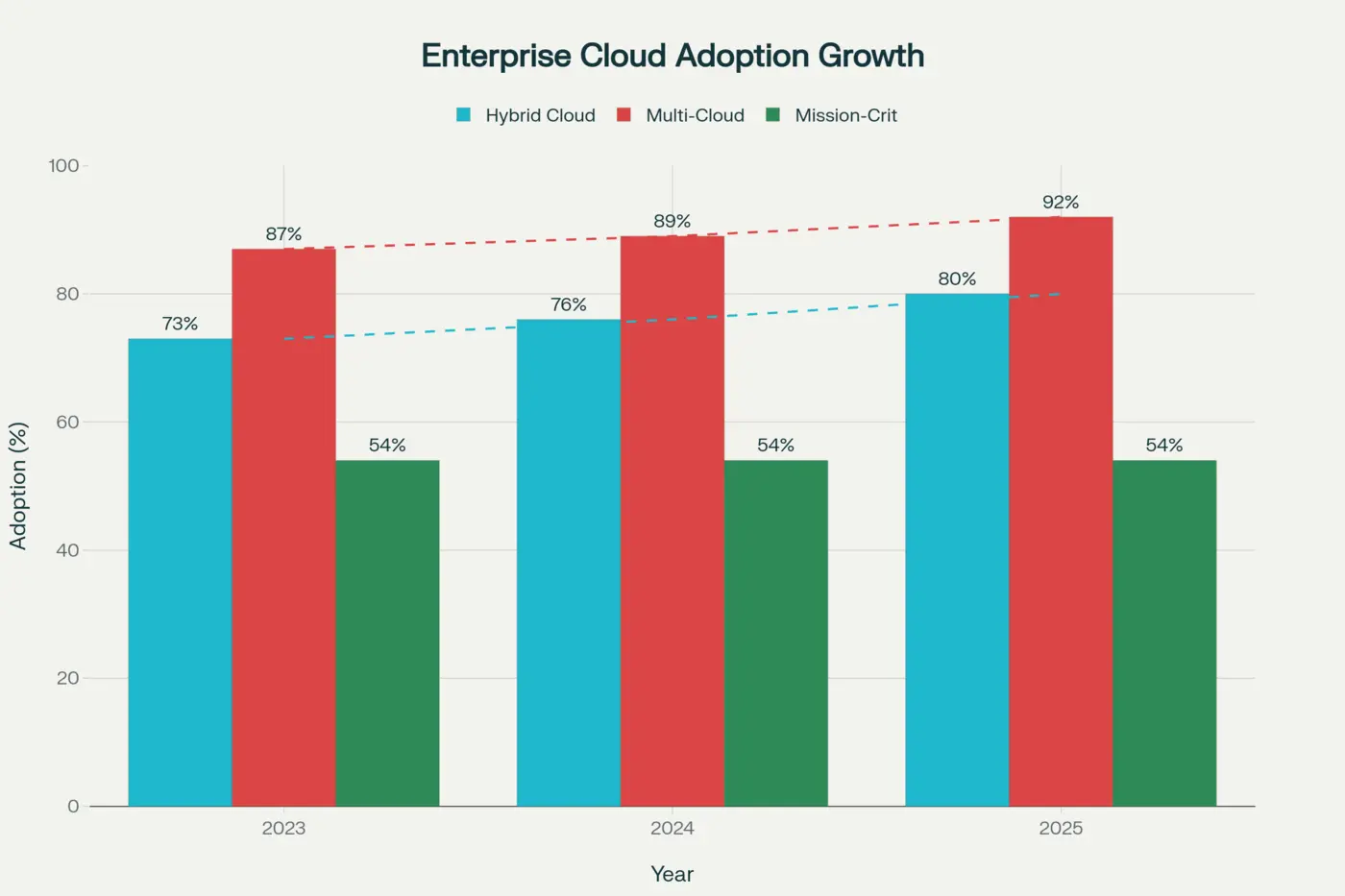
- 87% of organizations have implemented multi-cloud strategies
- 92% of enterprises have adopted approaches spanning multiple cloud providers
- 54% of enterprises use hybrid cloud specifically for mission-critical workloads
- 80% in 2025 (up from 73% in 2023)
The trend is clear: enterprises are waking up to a reality that technologists have known for years: single points of failure are unacceptable.
Why This Shift is Accelerating
The past two years have given enterprises plenty of reasons to rethink their architecture:
The AWS Outage (October 2025) When AWS US-EAST-1 failed, it wasn't one company that went down. It was thousands. Slack, Atlassian, Barclays, Lloyds. All gone. An entire region of one cloud provider took down a meaningful portion of the internet. Companies using hybrid cloud? They had failover paths.
The Azure Outage (October 2025) Days later, Azure's global DNS and load balancing systems failed. Microsoft 365 went down. Xbox went down. 18,000+ users reported issues. Again, companies with hybrid or multi-cloud architectures had alternatives. Companies with all eggs in one basket? They lost revenue.
The GitHub Outage (November 18, 2025) GitHub went down for approximately 3 hours, with over 5,000 reports. GitHub Actions stopped running. CI/CD pipelines failed. Copilot went dark. Developers couldn't deploy fixes, not for issues caused by other outages happening simultaneously. This demonstrated a critical vulnerability: when your deployment pipeline is a single point of failure, you cannot recover from anything.
The Cloudflare Outage (November 18, 2025) The same day as GitHub, Cloudflare went down for 6 hours with over 11,000 reports. X, ChatGPT, Spotify, and thousands of smaller services all displayed error 500. The root cause was simple: a database permissions change caused a configuration file to exceed a hardcoded memory limit of 200 features. This triggered a Rust panic that cascaded across their global network. Two major infrastructure providers failing on the same day revealed that our entire infrastructure ecosystem has become a Jenga tower: remove one piece and multiple towers topple.
The Business Case Has Never Been Clearer
After these outages, C-suite executives are asking questions:
- "How much revenue did we lose?"
- "Could we have prevented this with a different architecture?"
- "What's the cost of 99.99% uptime vs. the cost of being completely dependent on one provider?"
The answer, consistently, is: Hybrid cloud is cheaper than downtime.
Consider the math:
- Building hybrid cloud infrastructure: $500K - $2M depending on scale
- Revenue lost during one hour of total outage: $1M - $10M+ for most enterprises
- Likelihood of major cloud outage in any given year: Rising (as evidenced by 2025)
One major outage pays for years of hybrid cloud infrastructure. Companies are calculating this. They're deciding it's not worth the risk.
What Hybrid Cloud Adoption Looks Like in Practice
Enterprises moving to hybrid cloud in 2025 are typically following this pattern:
Tier 1 Workloads (Most Critical)
- Mission-critical databases: On-premises + replicated to cloud backup
- Authentication systems: On-premises + cloud fallback
- Real-time trading/manufacturing systems: On-premises for latency, cloud for backup
Tier 2 Workloads (Important but Flexible)
- Analytics and reporting: Cloud for scalability
- Development/test environments: Cloud for elasticity
- Non-customer-facing processing: Wherever cost is optimal
Tier 3 Workloads (Experimental)
- AI/ML experiments: Cloud GPUs
- New product prototypes: Cloud only, minimal risk if they fail
- Non-critical services: Cloud for startup speed
This isn't randomly throwing workloads into the cloud. This is strategic placement of workloads based on risk, latency, compliance, and cost.
Part 5: How to Build Your Hybrid Cloud Strategy. A Practical Playbook
So you've read the news. You've seen the outages. You've decided hybrid cloud is the right move for your company.
Now what?
Here's a practical playbook for building a hybrid cloud strategy that works.
Step 1: Audit Your Current State (2-4 weeks)
Before you move anything, you need to understand what you have.
Create a workload inventory:
- What applications are running?
- Where are they running today?
- How much traffic do they handle?
- What data do they process?
- How sensitive is that data?
- What compliance requirements apply?
- What's their current uptime?
Create a dependency map:
- What SaaS tools does each application depend on?
- What cloud services are in use?
- What's the criticality of each dependency?
- What happens if each dependency fails?
This audit is crucial because it reveals where your risks are. You might discover that 30% of your revenue flows through a single SaaS tool hosted on one cloud provider. That's your first target for remediation.
Step 2: Define Your Resilience Requirements (1 week)
Not everything needs 99.99% uptime. Define what you need:
Mission-Critical Systems (99.95%+ uptime required)
- Revenue-generating applications
- Core customer-facing services
- Authentication systems
- Payment processing
- These need hybrid or multi-cloud with automatic failover
Important Systems (99.5%+ uptime required)
- Internal tools teams depend on
- Analytics and reporting
- Backup systems
- These use hybrid cloud or cloud with good backups
Nice-to-Have Systems (95%+ uptime acceptable)
- Development environments
- Experimental projects
- These run entirely in public cloud
This categorization guides your architecture. Don't over-engineer systems that don't need it. Don't under-engineer systems that do.
Step 3: Choose Your Infrastructure Model (2-4 weeks)
You have options:
Option A: On-Premises + Public Cloud Hybrid
- Keep critical systems in your own data center
- Use public cloud for overflow, elasticity, and specialized services
- Best for companies with sensitive data, latency requirements, or compliance constraints
- Cost: $500K - $2M+ depending on scale
Option B: Private Cloud + Public Cloud Hybrid
- Use a private cloud provider for sensitive workloads
- Use AWS/Azure/GCP for less sensitive workloads
- Similar benefits to on-premises but less operational overhead
- Cost: Similar to Option A
Option C: Multi-Cloud (AWS + Azure + GCP)
- Distribute workloads across multiple public cloud providers
- Reduces vendor lock-in and provider outage risk
- More complex to manage
- Cost: Higher due to duplication and complexity
- Best used with Option A or B for maximum resilience
Most enterprises choose a combination: hybrid on-premises/private cloud for critical systems, multi-cloud for redundancy, and pure public cloud for experimental workloads.
Step 4: Establish Direct Connectivity (4-8 weeks)
This is crucial. You need resilient hybrid cloud with dedicated connections, not the public internet.
Set up dedicated connections:
- AWS Direct Connect: Dedicated network connection to AWS regions
- Azure ExpressRoute: Dedicated connection to Azure
- Google Cloud Interconnect: Dedicated connection to Google Cloud
These are not free, but they're not expensive either. DirectConnect typically costs $0.30/hour ($2,200/month) depending on capacity. This is trivial compared to revenue loss during outages.
Direct connectivity provides:
- Consistent, predictable network performance
- Lower latency for hybrid workloads
- Better security (traffic doesn't cross the public internet)
- More control over your network
Step 5: Pilot with Non-Critical Workloads (4-8 weeks)
Don't start by moving your most critical system. Start with something that has low risk and high learning value.
Good pilot candidates:
- Development environments
- Analytics dashboards
- Internal tools (HR systems, finance dashboards)
- Backup/archival systems
The goal is to:
- Learn your operational model
- Train your team
- Test your connectivity and failover procedures
- Build internal expertise before you rely on it for critical systems
Run disaster recovery tests. Simulate what happens if your data center loses connectivity. Does it fail over to the cloud? How quickly? Do you need automation?
Step 6: Establish Failover Procedures (2-4 weeks, ongoing)
Once you have hybrid infrastructure, you need procedures for when things go wrong.
Create runbooks for common failures:
- "Data center loses connectivity: here's what we do"
- "Cloud region goes down: here's what we do"
- "SaaS provider (Okta/Stripe/etc.) goes down: here's what we do"
Automate failover where possible:
- DNS automatic failover
- Load balancer automatic failover
- Database replication and failover
- Application-level circuit breakers
Manual failover is risky. The goal is to make most failures automatic.
Step 7: Test, Test, Test (Ongoing)
The best disaster recovery plan is one that's been tested.
Quarterly disaster recovery exercises:
- Simulate a data center outage. How quickly does it fail over? How much data do you lose?
- Simulate a cloud region outage. Do systems recover?
- Simulate authentication provider outage. Do you still serve customers?
- Simulate payment processor outage. What's your fallback?
These tests will reveal gaps in your procedures. Fix them before a real outage happens.
Step 8: Migrate Critical Workloads (Ongoing, months to years)
Once you've piloted and tested, gradually migrate your mission-critical systems to hybrid or multi-cloud.
Priority order:
- Systems with highest revenue impact if down
- Systems with largest outage history
- Systems with most complex dependencies
- All other critical systems
Don't try to move everything at once. Phased migration reduces risk and allows your team to learn incrementally.
The Investment Pays for Itself
A hybrid cloud implementation typically costs:
- Infrastructure: $500K - $2M (one-time)
- Operational overhead: $200K - $500K annually
- Total Year 1 cost: ~$700K - $2.5M
The business case:
- Revenue loss from one hour of total outage: $1M - $10M+
- Probability of major outage per year: Rising (as evidenced by 2025)
- Break-even point: 1-2 outages prevented
Given that the major cloud providers had multiple significant outages in 2025 alone, hybrid cloud infrastructure typically pays for itself within the first year by avoiding one extended outage.
Conclusion: Start Now
Cloud works. But relying on it exclusively is a bet against probability.
The events of 2025 (four major outages in a 30-day period, including two on the same day) have made one thing clear: resilience has to be architected. It cannot be delegated.
The companies winning in 2025 and beyond are the ones building hybrid cloud infrastructure. Not because they're stuck in the past, but because they're securing their future.
The question isn't whether to build hybrid cloud. The question is how quickly you build it.
Because the next outage is coming. And when it does, the companies with hybrid infrastructure will stay up while everyone else watches their revenue disappear.
How ZSoftly Helps
At ZSoftly, we specialize in helping mid-market companies build resilient, hybrid cloud architectures. Our services are designed to accelerate the playbook outlined above:
- Hybrid Cloud Assessment (Steps 1 & 2): We audit your workloads, create dependency maps, and define your resilience requirements, so you know exactly where your risks are
- Architecture Design & Connectivity (Steps 3 & 4): Custom hybrid cloud blueprints with direct connections (AWS Direct Connect, Azure ExpressRoute) tailored to your compliance and performance needs
- Pilot & Implementation (Steps 5 & 8): Hands-on deployment starting with non-critical workloads, then systematically migrating your mission-critical systems
- Disaster Recovery Automation (Steps 6 & 7): Failover automation, runbook creation, and quarterly DR testing to ensure you're always prepared
The next outage is coming. Don't wait for it to expose your vulnerabilities. Contact us to start building your hybrid cloud strategy today.