
We had a cost problem hiding in plain sight. Eight EC2 instances running 24/7. Most of them idle overnight.
The breakthrough came when we asked the right question: What if we organized infrastructure by operational pattern instead of application type?
Platform services that run continuously need different infrastructure than applications that scale to zero during off-hours. CI/CD runner managers that watch APIs 24/7 are platform services, not workload services.
This realization led us from 8 nodes to 3, cutting our sandbox costs from $260/month to $100/month while actually improving reliability.
TL;DR
We consolidated 8 nodes to 3 by separating services based on operational characteristics rather than application categories. Platform services got dedicated infrastructure. Applications scaled to zero overnight. CI/CD managers moved to platform nodes while ephemeral runners stayed on-demand.
Results:
- 62% cost reduction ($160/month savings in sandbox)
- 3 platform nodes running 24/7 on ARM64 spot instances
- 0 workload nodes during off-hours (9 PM - 8 AM)
- CI/CD managers separated from ephemeral runners
- All configuration managed via GitOps with ArgoCD
The Problem
Our sandbox EKS cluster started simple. One service, one node. Then we added observability. Then internal tools. Then CI/CD infrastructure.
By January 2026, we had 8 EC2 instances running continuously:
| Node Type | Count | Purpose | Monthly Cost |
|---|---|---|---|
| Platform (Mixed) | 4 | Databases, ingress, operators | ~$120 |
| Workload (ARM64) | 2 | Apps, CI/CD managers, monitoring | ~$60 |
| Workload (AMD64) | 2 | AMD64-specific CI/CD jobs | ~$80 |
| Total | 8 | Everything | ~$260 |
The waste became obvious at night. Application workloads scaled to zero between 9 PM and 8 AM. Yet all 8 nodes kept running.
Why? Platform services and CI/CD manager pods were scattered across workload nodes. Karpenter couldn't drain nodes because each had at least one critical pod blocking termination.
The Insight
We mapped every pod in the cluster to its runtime behavior. Three patterns emerged:
Pattern 1: Always-On Services
Ingress controllers. Database clusters. Observability stacks. Identity providers. Kubernetes operators. These never sleep. They need high availability.
Pattern 2: Business Hours Workloads
Internal tools like n8n, Vaultwarden, WikiJS, and Zammad. Nobody uses them overnight. They can scale to zero from 9 PM to 8 AM.
Pattern 3: On-Demand Compute
CI/CD runner pods that execute actual jobs. They spawn when workflows trigger. They terminate after job completion. Spot interruptions are acceptable because jobs retry.
The critical insight came when we looked at CI/CD infrastructure. We had been treating GitHub Actions listeners and GitLab runner managers as "workload services" because they were related to CI/CD.
Wrong axis.
Those manager pods watch APIs 24/7. They're lightweight orchestrators, not job executors. They need the same reliability as operators and ingress controllers.
They're platform services.
The Solution
Create a dedicated platform NodePool with a taint. Only platform services get scheduled there. Everything else goes to autoscaling workload nodes.
Before: Mixed Workloads
8 nodes running 24/7. Platform services scattered across all nodes. No node can drain because each has critical pods. Karpenter blocked from consolidating.
After: Separated by Operational Pattern
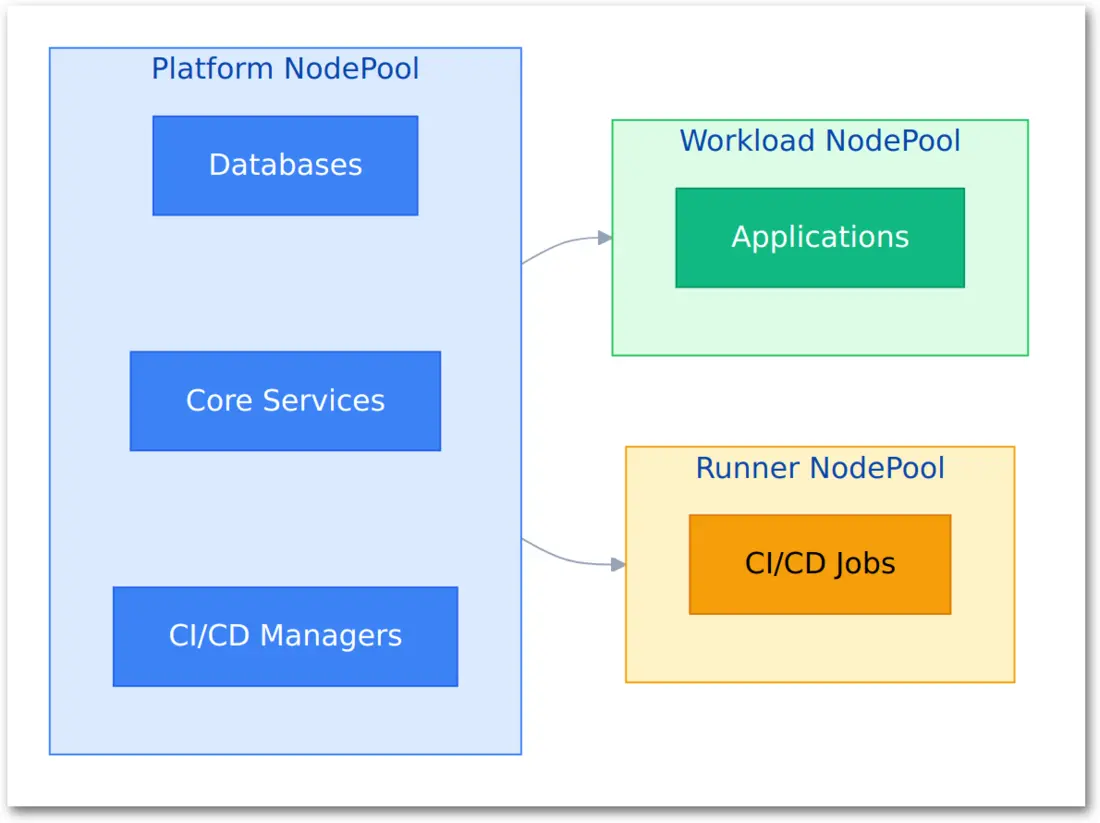
Platform NodePool (3 nodes, always running):
- Traefik, PostgreSQL, SigNoz observability stack
- Authentik identity provider
- Kubernetes operators (external-secrets, external-dns, KEDA, CNPG, ECK)
- CI/CD managers (GitHub Actions listeners, GitLab runner managers)
- System components (metrics-server, CoreDNS)
Workload NodePool (0 nodes during off-hours):
- Internal applications (n8n, Vaultwarden, WikiJS, Zammad)
- KEDA scales to zero from 9 PM - 8 AM
- Nodes drain and terminate when pods scale down
Runner NodePool (0 nodes when idle):
- Ephemeral CI/CD runner pods
- Spin up on-demand for jobs
- Nodes terminate after jobs complete
Implementation
The architecture looked simple on paper. The reality was messier: 27 platform services, each configured differently.
Creating the Platform NodePool
We started with infrastructure. Created a dedicated NodePool in Terraform with three critical decisions:
ARM64 Graviton4 instances. About 40% cheaper than x86 for equivalent performance. Our workloads are CPU-light, so the savings compound quickly.
Spot instances. Even for platform services. This felt risky at first. "What if spot gets interrupted during peak hours?" But we run 2-3 replicas of everything critical. Spot interruptions trigger pod rescheduling to healthy nodes. High availability covers spot risk.
Taints. The key mechanism. We added a platform-services=true:NoSchedule taint to platform nodes. This prevents workload pods from landing there accidentally. Only pods with the matching toleration get scheduled.
Minimum 3 nodes, maximum 6. EKS Auto Mode scales within that range based on pod resource requests.
Configuring Platform Services
This took longer than expected. Every Helm chart handles node affinity differently.
Standard charts use root-level nodeSelector and tolerations in values files. Traefik, external-dns, metrics-server all followed this pattern.
CloudNativePG clusters required nodeSelector nested under the affinity section. This is a CRD schema requirement. We initially put it at the root level and wondered why pods kept landing on workload nodes. Read the CRD documentation, found the right path.
Charts with global configuration (KEDA, External Secrets) simplified things. Set nodeSelector once at the global level, all components inherit it. Operator, webhooks, cert-controller all configured in one place.
ECK Elasticsearch was tricky. Helm doesn't deep-merge arrays. When you override the nodeSets array, you must provide the complete definition including count, config, resources, and volumeClaimTemplates. We lost configuration twice before realizing Helm was replacing the entire array.
Authentik's LDAP outpost broke the pattern entirely. The outpost Deployment is created dynamically by Authentik's controller, not by the Helm chart. We used Authentik blueprints to inject nodeSelector and tolerations as JSON patches. The blueprint system applies patches to resources created at runtime.
We documented every pattern in docs/platform-nodepool-config.md. Each time we configured a new service type, we added an entry. This became the reference when migrating to staging.
Separating CI/CD Managers from Runners
The critical architectural insight: manager pods are platform services.
GitHub Actions runner controller has two components:
- Listener pods - Lightweight processes that watch the GitHub API for workflow triggers
- Runner pods - Heavy compute that executes actual CI/CD jobs
We had been treating both as "workload infrastructure." Wrong. Listeners run 24/7. They're orchestrators, not workers. They belong on platform nodes.
Same pattern for GitLab runners. The runner manager pod registers with GitLab and spawns job pods. Manager stays up. Job pods are ephemeral.
Configuration was straightforward once we understood the separation. Listeners and managers get platform nodeSelector with tolerations. Runner pods get workload nodeSelector pointing to on-demand spot nodes.
GitHub's listener template had one gotcha: requires an explicit containers section even if empty. The chart merges defaults, but the schema validation fails without the field.
Enabling Time-Based Scaling
Applications needed to scale to zero overnight. We use KEDA (Kubernetes Event-Driven Autoscaling) with cron triggers.
Each application gets a ScaledObject that defines scale-down time (9 PM) and scale-up time (8 AM). KEDA watches the clock and adjusts replica counts.
When all application pods in a namespace terminate, EKS Auto Mode recognizes the nodes are empty and drains them. Nodes disappear within 10-15 minutes.
The key was timezone handling. KEDA's cron scaler supports timezone configuration. We use America/New_York to match business hours regardless of daylight saving time changes.
The Migration
We migrated incrementally over three weeks. One service at a time. GitOps for everything.
Week 1: Core Platform Services
Started with the foundation. Databases first: PostgreSQL clusters, ClickHouse, Zookeeper. These are stateful. If something goes wrong, rollback is harder.
Then ingress and DNS. Traefik and external-dns. These route all traffic. Migrating them meant brief connection drops during pod rescheduling.
Finally secrets and monitoring. External-secrets operator and the SigNoz observability stack. SigNoz is heavy: ClickHouse database, Zookeeper cluster, Redpanda message queue, OpenTelemetry collectors. Moving all components to platform nodes required careful coordination.
The workflow was consistent: Update values file with platform nodeSelector and tolerations. Commit to Git. Wait for ArgoCD sync. Delete the pod to force rescheduling. Verify the new pod landed on a platform node.
We caught configuration errors fast. ArgoCD would fail to sync, or pods would stay in Pending state. Fix the values file, push again, repeat.
Week 2: Operators and Controllers
Kubernetes operators next. KEDA, CloudNativePG, ECK (Elastic Cloud on Kubernetes). These manage other resources. Disruptions here cascade to workloads.
Then CI/CD controllers. This was the moment of truth: migrating GitHub Actions listeners and GitLab runner managers to platform nodes. We tested in sandbox first, verified listeners stayed up during pod migration, confirmed workflows still triggered correctly.
System components last. Metrics-server (required for HPA). CoreDNS (cluster DNS).
CoreDNS was different. It's managed by EKS, not by our ArgoCD applications. We patched it directly using kubectl. Not GitOps, but unavoidable. EKS manages the Deployment.
Week 3: Application Scaling
With platform services stable on dedicated nodes, we enabled time-based scaling for applications.
Started with n8n (workflow automation). Single deployment, no dependencies. Enabled KEDA CronScaler. Verified it scaled to zero at 9 PM. Waited overnight. Checked node count in the morning: 6 nodes down to 3. Success.
Repeated for Vaultwarden (password manager), WikiJS (internal docs), and finally Zammad (ticketing system with 8 separate components).
Each application followed the same pattern: enable cost optimization in values file, commit, wait for ArgoCD sync, verify KEDA ScaledObject created, test manual scale-down to ensure Karpenter consolidated nodes.
By the end of week 3, nodes dropped from 8 to 3 every night. Rose back to 5-6 during business hours when applications scaled up.
Results
| Metric | Before | After | Change |
|---|---|---|---|
| Total Nodes | 8 | 3 | -62% |
| Platform Nodes | 0 dedicated | 3 (ARM64) | New |
| Workload Nodes | 6 (24/7) | 0 (off-hours) | -100% |
| Runner Nodes | 2 (24/7) | 0 (idle) | -100% |
| Monthly Cost (Nodes) | ~$260 | ~$100 | -62% |
| Spot Instance Use | 50% | 100% | +50% |
| Node Consolidation | Blocked | Active | Fixed |
| Off-Hours Nodes | 8 | 3 | -62% |
| CI/CD Manager Uptime | Inconsistent | 100% | Improved |
Cost breakdown:
- Before: 8 nodes × $1.10/day (spot avg) = ~$260/month
- After: 3 nodes × $1.10/day = ~$100/month
- Savings: $160/month (~$1,920/year) for sandbox alone
Multiply by environments:
- Sandbox: $160/month savings
- Development: Similar pattern = ~$160/month
- Staging: Larger workloads = ~$300/month
- Total savings: ~$620/month = ~$7,440/year
Lessons Learned
1. Separate by Operational Characteristics, Not App Type
We initially separated "platform" from "apps." Wrong axis. The real distinction is operational pattern:
- 24/7 services go to platform nodes (no matter if it's a database or a CI/CD controller)
- Time-based workloads go to workload nodes that scale to zero
- Ephemeral compute goes to on-demand runner nodes
CI/CD manager pods are platform services. They watch APIs 24/7. Treat them like operators.
2. Chart-Specific nodeSelector Paths
There's no standard. Each chart does it differently:
| Chart Type | nodeSelector Path | Notes |
|---|---|---|
| Standard Helm | nodeSelector | Root level |
| CloudNativePG | affinity.nodeSelector | CRD schema requirement |
| KEDA | global.nodeSelector | Applies to all components |
| External Secrets | global.nodeSelector | Covers operator + webhook |
| ECK Elasticsearch | nodeSets[].podTemplate | Complete array override needed |
| GitHub Actions (ARC) | listenerTemplate.spec | Requires containers field |
| GitLab Runner | nodeSelector + config | Manager vs runner pods |
| Authentik Outpost | Blueprints (json patches) | Dynamically created resources |
Lesson: Always test with helm template locally before pushing to ArgoCD.
3. Helm Doesn't Deep-Merge Arrays
When you override arrays in Helm values (nodeSets, initContainers, volumes), you must provide the complete array. Helm replaces, not merges.
We learned this with ECK Elasticsearch. Added nodeSelector to the podTemplate section. ArgoCD synced successfully. Pods went to Pending state. Turns out we'd lost the resource limits, volume claims, and Elasticsearch configuration. Helm replaced the entire nodeSets array with our nodeSelector override alone.
The fix: provide the complete array definition including count, config, podTemplate, and volumeClaimTemplates. Verbose, but necessary.
4. EKS Auto Mode vs Karpenter
We use EKS Auto Mode (AWS-managed scaling), not self-hosted Karpenter. Differences:
| Feature | Karpenter | EKS Auto Mode |
|---|---|---|
| Consolidation timing | Configurable | AWS-controlled |
| NodePool configuration | CRDs | Terraform/API |
| Spot interruptions | User-managed | AWS-managed |
| Control plane | User-managed | Fully managed |
Consolidation timing: EKS Auto Mode typically drains empty nodes within 10-15 minutes. Slower than Karpenter but requires zero operational overhead.
5. GitOps or Manual Patches?
Everything via GitOps. We initially considered using kubectl patch for the GitHub Actions listeners but caught ourselves:
- [NO] kubectl patch: Lost on next ArgoCD sync. No audit trail.
- [YES] GitOps: Tracked in Git. Reproducible. Auditable.
The only exception: CoreDNS (managed by EKS). For everything else, update the Helm values and let ArgoCD sync.
6. Test Consolidation in Sandbox First
We validated the entire workflow in sandbox before touching production:
- Configure platform NodePool
- Migrate one service at a time
- Verify pod placement with
kubectl get pods -o wide - Scale down workloads manually, wait for consolidation
- Re-enable autoscaling and verify overnight behavior
7. Document Configuration Patterns
We created docs/platform-nodepool-config.md to track chart-specific patterns. Every time we configured a new service, we added an entry.
This became the reference guide when migrating to staging and production.
What We'd Do Differently
Use ARM64 Everywhere
We kept AMD64 nodes for edge cases. Turns out, everything we run supports ARM64:
- PostgreSQL, ClickHouse, Elasticsearch: Native ARM64 builds
- SigNoz, Authentik, Traefik: Multi-arch images
- GitHub Actions, GitLab runners: ARM64-compatible
Next step: Eliminate AMD64 nodes entirely. Migrate the few AMD64-only CI jobs to GitHub-hosted runners or build ARM64-compatible containers.
Start with Platform NodePool
If we were starting fresh, we'd create the platform NodePool on day one. Separating 24/7 services from workloads should be the default architecture, not an optimization.
Automate nodeSelector Configuration
We manually updated 27 values files. One at a time. Copy-paste the nodeSelector block. Copy-paste the tolerations. Commit. Push. Repeat.
Should have written a script using yq to inject the platform scheduling configuration programmatically. Would have saved hours and eliminated typos.
Next Steps
We're taking this architecture to production with a few improvements:
- Multi-zone platform nodes: 3 nodes across 3 AZs for higher availability
- Reserved instances for platform nodes: 1-year commitment for base capacity
- Dedicated observability NodePool: SigNoz generates high disk I/O, separate from other platform services
- Automated cost reports: Track per-NodePool costs with Kubecost
Need help optimizing your AWS EKS costs? As an AWS Partner, ZSoftly provides Kubernetes consulting and platform engineering services for Canadian companies. We specialize in cost optimization, GitOps adoption, and CI/CD modernization. Talk to us
Sources
- EKS Auto Mode Documentation - AWS EKS
- Karpenter Node Consolidation - Karpenter
- KEDA Cron Scaler - KEDA
- GitHub Actions Runner Controller - GitHub
- CloudNativePG Documentation - CloudNativePG
- ArgoCD Best Practices - ArgoCD

